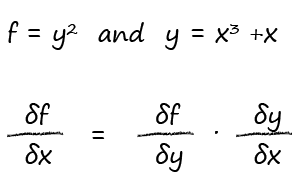I must have read dozens of tutorials and papers, tens of slides and presentations, and a handful of proper academic textbooks too. And none of them seemed to explain well why the squared error function is used, and most read as if there could be no other choice.
This blog explores this question, poses a "naive" alternative derived from first principles, and demonstrates that it seems to work.
Basics
Let's recall some basics.- Neural networks are trained by adjusting the link weights.
- The key factor that informs these adjustments is how "wrong" the untrained network is.
- The actual output and the desired output (training examples) will be different in an untrained network.
- This difference (target - actual) is the error. There is an error for each output layer node.
Cost Function
During network training, the weights are adjusted guided by a cost function. A cost function is a way of expressing how good or bad a neural network is. The shape of a cost function guides how weights need to change to improve the network's performance.
Intuitively, you can see that the cost function must be in some way related to the error above.
Intuitively, you can see that the cost function must be in some way related to the error above.
Most guides will use the following cost function to minimise
$$Cost=\sum_{output\_nodes}(target−actual)^2$$
They often don't give a solid clear reason for this function, but if they do say anything it is the following:
I challenge each of the above points in turn:
The following are the steps for deriving a weight update expression from a simpler naive cost function that isn't the squared error function.

From both directions? Let's unfold that a bit more.
If the error at a node $e_j=(t_j−o_j)$ is positive, and the gradient with respect to weight $w_k$ is positive, we reduce the weight. If the gradient is negative, we increase the weight. In this way we inch towards zero error.
The opposite applies if the error is negative. If the gradient is positive we increase the weight a bit, and if it is negative, we decrease the weight a bit.
The following diagram illustrates this gradient ascent or descent towards zero from both directions, and compares it with the descent only using the squared error cost function.

We've only derived the weight update expression for the link weights between the hidden and output layer of a node. The logic to extend this to previous layers is no different to normal neural network backpropagation - the errors are split backwards across links in proportion to the link weight, and recombined at each hidden layer node. This is illustrated as follows with example numbers:

Here's the Python notebook for a neural network learning to classify the MNIST image data set using the normal squared error cost function. The basic unoptimised code achieves 97% accuracy on the 10,000 test set.
Python Notebook - gradient descent to minimise squared error. 97% success.
Now here's the same Python notebook but altered to to gradient ascent and descent aiming to zero the naive cost function.
Python Notebook - gradient ascent and descent to zero naive error. 93% success.
The size of this accuracy at 93% over the 10,000 test data instances from the MNIST set means this isn't a lucky fluke. This works.
My next thoughts are ... what are the advantages of this grad ascent/descent?
But I might be very very mistaken. Do get in touch on twitter @myoneuralnet
$$Cost=\sum_{output\_nodes}(target−actual)^2$$
They often don't give a solid clear reason for this function, but if they do say anything it is the following:
- the $(target - actual)^2$ is always positive so errors of different signs don't cancel out, potentially misrepresenting how "wrong" the network is. For example, errors of +2 and -2 from output nodes would sum to zero, suggesting a perfectly correct output where it is in fact clear the output nodes are in error.
- the cost function is differentiable so we can work out the sensitivity of the error to individual weights, the partial differential $$\frac{\partial {Cost}}{\partial {w}}$$
- parallels to linear regression, where errors are assumed to be Gaussian, that is, distributed normally around the true value.
Challenge
I challenge each of the above points in turn:- We don't need the cost function to always be positive because we don't actually sum over the errors from each output node. Instead we consider each output node in turn and in isolation from any other output node when we propagate the errors back.
- You can find $\frac{\partial {Error}}{\partial {w}}$ from the simpler naive $Error=(target−actual)$. There is no problem deriving the partial differentials from this $Error$ expression. Instead of trying to minimise it, we instead move towards zero from either direction. We're trying towards zero $Error$, not to get it to ever lower values below zero.
- There is no reason to believe the errors in the output of a neural network are distributed normally.
Weight Learning from a Naive Cost Function
The following are the steps for deriving a weight update expression from a simpler naive cost function that isn't the squared error function.
- Consider only one output node of a neural network, the $jth$ node.
- The error at the $jth$ output node is $(target - actual)$, or $e_j=(t_j−o_j)$.
- The actual output, $o_j=sigmoid(\sum{w_i.x_i})$ where $w_i$ is the weight of the $ith$ link to that $jth$ node, and $x_i$ is the output from the preceding $ith$ node. The $sigmoid(x)$ is the popular squashing function $\frac{1}{(1+e^{−x})}$.
- So $$\frac{\partial {e_j}}{\partial {w_k}} = \frac{\partial}{\partial{w_k}}(t_j - o_j) = \frac{\partial}{\partial{w_k}}(- sigmoid(\sum_{i}w_i.x_i))$$ because we can ignore the constant $t_j$. We can also see that only one $w_{i=k}$ matters as other $w_{i≠k}$ don't contribute to the differential. That simplifies the sum inside the sigmoid.
- That leaves us with $$\frac{\partial {e_j}}{\partial {w_k}} = \frac{\partial}{\partial{w_k}}(- sigmoid(w_k.x_k)) = −(w_k.x_k)(1−w_k.x_k).x_k$$ because we know how to differentiate the sigmoid.
From both directions? Let's unfold that a bit more.
If the error at a node $e_j=(t_j−o_j)$ is positive, and the gradient with respect to weight $w_k$ is positive, we reduce the weight. If the gradient is negative, we increase the weight. In this way we inch towards zero error.
The opposite applies if the error is negative. If the gradient is positive we increase the weight a bit, and if it is negative, we decrease the weight a bit.
The following diagram illustrates this gradient ascent or descent towards zero from both directions, and compares it with the descent only using the squared error cost function.

We've only derived the weight update expression for the link weights between the hidden and output layer of a node. The logic to extend this to previous layers is no different to normal neural network backpropagation - the errors are split backwards across links in proportion to the link weight, and recombined at each hidden layer node. This is illustrated as follows with example numbers:

Does It Work? ... Yes!!
I coded the necessary changes into the existing neural network python code, and the results compare really favourably.Here's the Python notebook for a neural network learning to classify the MNIST image data set using the normal squared error cost function. The basic unoptimised code achieves 97% accuracy on the 10,000 test set.
Python Notebook - gradient descent to minimise squared error. 97% success.
Now here's the same Python notebook but altered to to gradient ascent and descent aiming to zero the naive cost function.
Python Notebook - gradient ascent and descent to zero naive error. 93% success.
The size of this accuracy at 93% over the 10,000 test data instances from the MNIST set means this isn't a lucky fluke. This works.
My next thoughts are ... what are the advantages of this grad ascent/descent?
- Do we lose some information by the act of squaring? Because we've lost the +ve and -ve aspects?
- Should we stick to the squared error because the actual accuracy was slightly higher when compared like for like?
- Why are the actual output values much better polarised towards the extremes of zero and one using this naive function? With learning rate 0.3 the test of item 20 in the test set results in a stark output histogram.
Did I Go Wrong?
For me this challenges the unquestioning acceptance of the squared error cost function.But I might be very very mistaken. Do get in touch on twitter @myoneuralnet
Update
Thanks to help from the London Kaggle Meetup the following is now clear to me:- The naive error function has a gradient that is linear, and trying to optimise it by moving towards zero is the same as trying to move to the bottom zero of the absolute value error $|target-outout|$.
- The refinements are not as efficient as the size of the step is constant - which risks bouncing about the minimum or the zero.
- You could mitigate this by moderating the step size in proportion to the closeness to the target. This means multiplying the step change by the error $(target-output)$. This in effect is the same calculation as that from the squared error cost function!