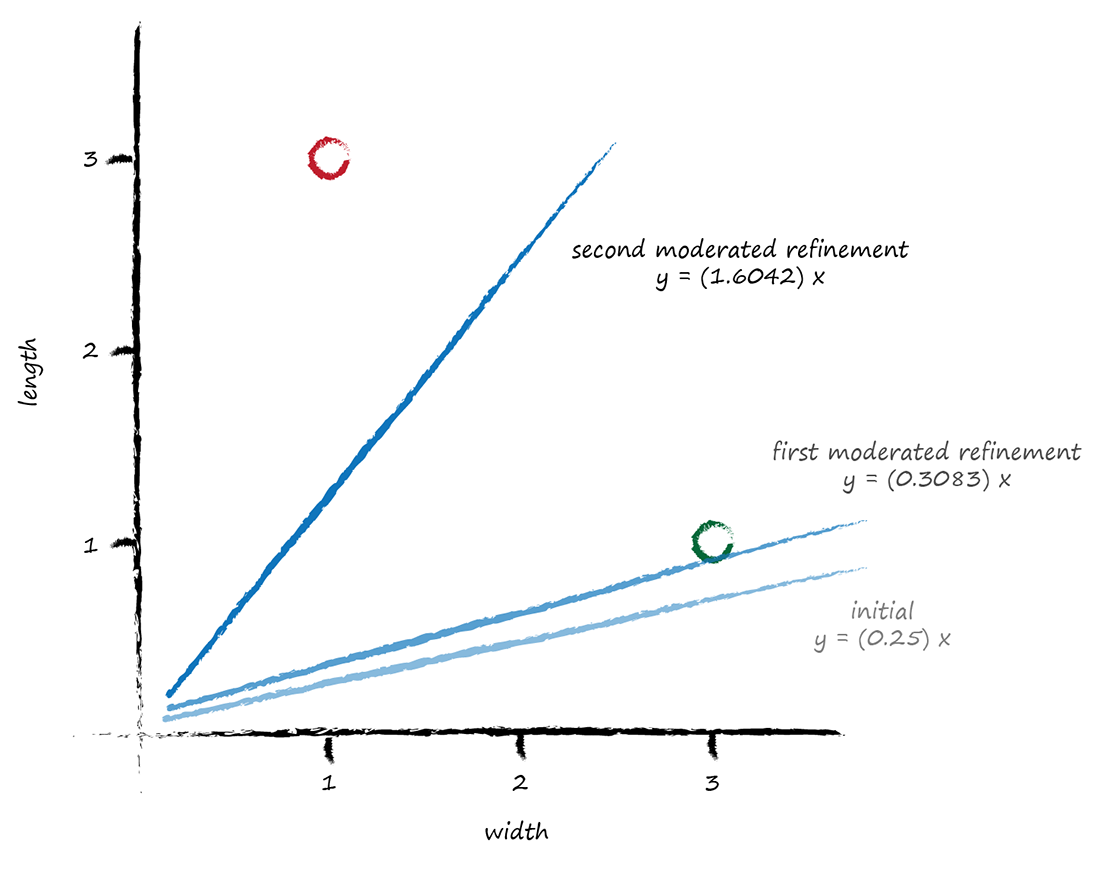
Update: the link between the phase rotated by these neurons and frequency components of an image is not clear. Needs more work ...
There are many ways to change the popular model of neural networks to see if we can improve how they work.
For example, we could change the activation function, or how nodes are connected to each other, or try different error functions. These things are being done fairly often and aren't considered that radical.
The following talks about a much deeper, more fundamental change.
1. From Real Numbers to Complex Numbers
Complex numbers are a richer set of numbers than the normal real numbers that we predominantly use in neural networks.
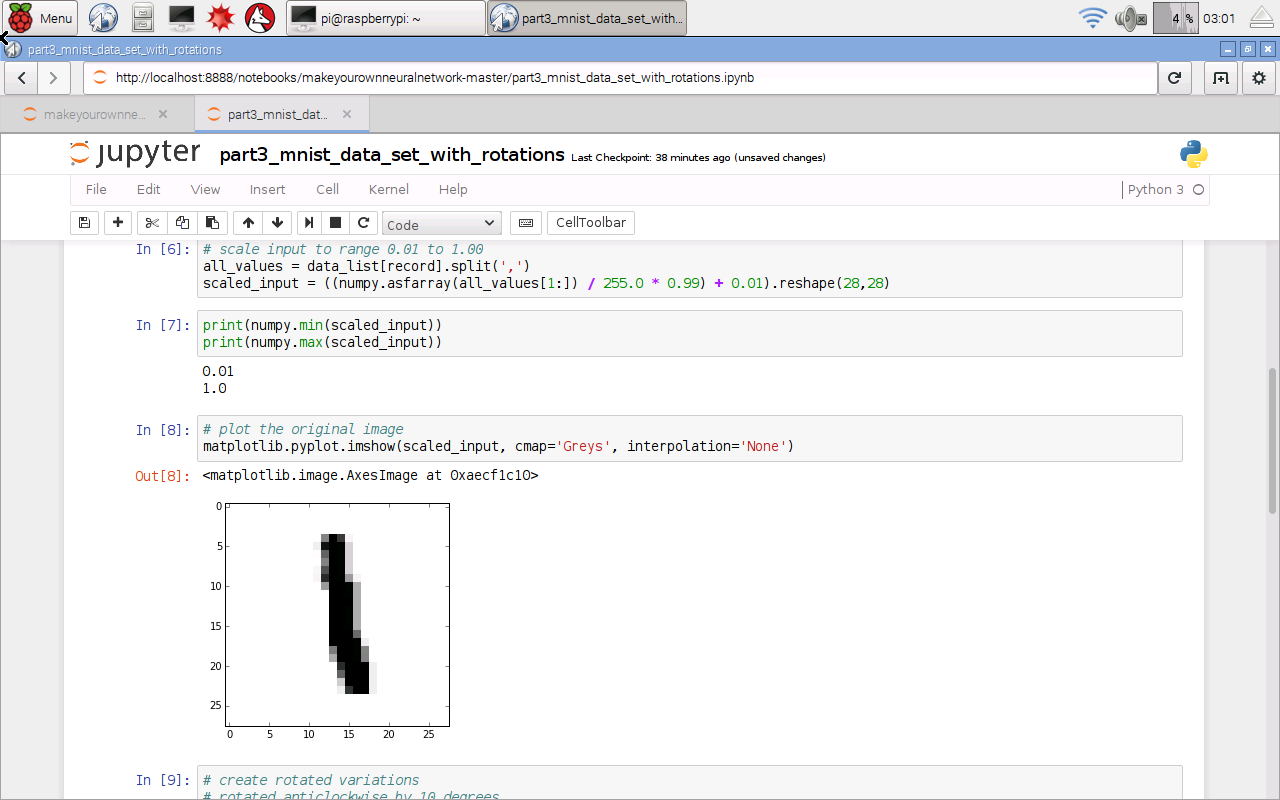
They have a higher dimensionality which should allow much more complicated relationships to be learned by a neural network.
We know that often have to recast a problem into a higher dimensional space in order for a learning method to work - such as projecting 1-dimensional XOR data into a higher dimensional space so that a linear, but higher-dimensional, threshold can partition the data.
Is it enough to simply replace the use of real values with complex values, and keep everything else the same - the same activation function, the same error function, the same system of link weights, etc? Hmmmm ...
2. Complex Valued Link Weights
The first idea of a thing to upgrade from normal real numbers to complex values is the link weights.
That itself is actually a massive change because now signals are not just amplified or diminished as they pass through a network, they can now be
rotated too.
This is a significant step change in the richness of what a neural network can do to the signals - some call this
higher functionality. It should lead to a richer ability to learn more complex relationships in training data.
Why rotation? Because multiplying by a complex number doesn't just change a value's magnitude, it can also change the direction ... a rotation. A simple example is multiplying by (0+1j) rotates a value anti-clockwise by 90-degrees ($\pi /2$ radians).
If we're now processing complex values, we need to think again about the nodes too. Do they need to change as well?
3. Complex Neural Nodes
Traditional neural network nodes do two things. They sum up the incoming signals, moderated by the link weights, and they then use an activation function to produce an output signal. That activation function has historically been S-shaped or step-shaped to reflect how we thought biological neurons worked.
We could keep that as it is. And some researchers have tried that - trying to use the logistic function $1/(1+e^{-x})$, or the $tanh()$ function, with complex inputs. Some problems arise from this, though. The calculations are not easy. The gradient isn't trivial to calculate to do gradient descent, if at all
(not an expert but iirc you can't differentiate it wrt complex values). There isn't a great fit between rotating signals and an activation threshold function that assumed a simple incoming signal whose magnitude was the only thing of importance.
So let's be radical and try something very different.
Let's force the signal to have a magnitude of 1, but allow it to rotate. That means we are working with signals that only sit on the unit circle in the complex domain. In essence we've discarded the magnitude and kept the phase.
This may seem radical, but isn't really when you think about it. We hope the benefits of the complex domain are in the ability for signals to rotate around. Absolute magnitude was never that important anyway in traditional neural networks as we routinely normalised signals, and it was the relative magnitude at the output layer that was used for eventually deciding on a category or class. Remember the logistic and $tanh()$ activations squish the signal's magnitude into a specific range, irrespective of the incoming magnitude.
So what does a complex node's activation function do? It doesn't really need to do anything more that what we've just described. The incoming signals have already been rotated by the complex weights, so all that remains is to make sure the sum is rescaled back to a unit circle.
That's it!
Here's what we've just said, in mathematical notation:
1. Combine incoming signals to a node $$ z = \sum_{n}{w_n \cdot x_n} $$
2. Rescale back to the unit circle $$ P(z) = \frac{z}{|z|} = e^{j * arg(z)} $$
Preparing Inputs, Mapping Outputs
Ok so in our mind we've designed a machine which kinda has lots of cogs in it, rotating the signals as they pass through. And we've said that we're constraining these signals to a magnitude of 1, that is, they're always on a unit circle.
How does this work with inputs that might be from the real world, and not complex numbers on a unit circle? And what about the answers we want from a neural network? We might want a network to give us answers that are larger real numbers, or maybe even classification categories with names like "dog, cat, mouse".
From our work on traditional neural networks, we've already seen the need to prepare inputs, and also to map the outputs.
Inputs
Inputs need to map to the complex unit circle. Why? Imagine we had a super-simple network of only one node. That node takes the input and needs to map that to an answer. To do this, it needs to do something to that data, a transformation, the application of a function. To give the node the best chance of learning to do this, the incoming data should be as best spread out over that transformation's domain space as possible. We know that relatively low variance can hinder learning.
Input values that run only along the real axis (imaginary part is zero) have only 2 possible phases - 0 or $\pi$ radians. For a network, or indeed a node, that tries to work with phases in order to make a decision, this is extremely limiting. So we need to map the inputs to the unit circle and cover a good range of phases. How we do this depends on the specifics of a particular problem, but a good starting point is to linearly remap the minimum of the input values to $e^{j \cdot \theta=0}$, and the maximum to $e^{j \cdot \theta=2\pi}$.
In some scenarios the input values shouldn't wrap around. That is, if we had categories like the letters A to Z, then A is not semantically close to Z, but would be when mapped to the unit circle. We can insert a mapping gap - to ensure that a small change in A doesn't lead to Z.
If we have categories, rather than a continuum of input values, then it makes sense to divide the unit circle into sectors. For example, insect body lengths are a continuum, and so can map to the unit circle fairly easily. Insect names, however are words, not continuous real numbers, so we need to take hard firm slices of the circle, as illustrated further down.
Outputs
In a similar way, we can map a node's output back to meaningful values, labels or classes.
If we had a continuum of real numbers, we can simply reverse the previous mapping back from the unit circle.
If we have nominal categories, we slice up the circle into sectors, as shown in the diagram below. You can also see why a sector's bisector should be the target value for training. Easy!

Aside: Phase is Important
Phase is incredibly important in signals from the real world. Let's illustrate how important.
Take an image of something from the real world, and decompose the signal into its frequency phase and magnitude. You might recognise this as taking a
Fourier transform. If we reconstruct the image as follows:
- ignore the phase (set it all to 0), just use the magnitude
- ignore the magnitude (set it all to 1), just use the phase
we find the the phase contains most of the information we use to understand an image - not the magnitude.
Code to demonstrate this working is on
github - it shows clearly that there is much more recognisable information in the phase part of an image's Fourier transform.
This exercise illustrates quite powerfully the importance of phase, and why a neural network based on processing and learning phase might be a good idea, particularly for image recognition tasks.
Learning Algorithm
We changed the activation function from an sigmoid shaped real function to a mapping of a signal to the unit circle. What does this mean for our learning algorithm?
The first thing to realise is that the mapping $P(z) = \frac{z}{|z|} = e^{1j*arg(z)}$ is not differentiable in the complex domain
(doesn't satisfy the Cauchy-Riemann conditions). Remember, we needed to differentiate the activation function so we could do gradient descent down the error function to find better and better weights.
We don't need to do that here.
That's right. We don't need to differentiate. Or do gradient descent.
Have a look at the following digram which shows the actual output from a complex node and what the target output should be. Also illustrated is the correction that's needed - the error.
Lets write out what's happening to the signal in symbols. From above, we already have:
$$ z = \sum_{n}{w_n \cdot x_n} $$
$$ P(z) = \frac{z}{|z|} = e^{1j * arg(z)} $$
Now suppose we had the correct weight adjustments $\Delta w_n$ to make the $z$ point in the same direction as the desired training target $t$. Actually we can make it not just point in the same direction, we can imagine we've got the magnitude spot on too.
$$ t = \sum_{n}{(w_n + \Delta w_n) \cdot x_n} $$
The error, which is the required correction, $e = t - z$, is
$$ e = \sum_{n}{(w_n + \Delta w_n) \cdot x_n} - \sum_{n}{(w_n) \cdot x_n} $$
Simplifying,
$$ e = \sum_{n}{\Delta w_n \cdot x_n} $$
Ok - that's a nice simple relationship. It tells us the error $e$ is made up of many contributions from the various $\Delta w_n \cdot x_n$. But we don't have any more clues as to which values of $\Delta w_n$ precisely. Right now, it could be one of many different combinations ... just like $1+4=5$, $2+3=5$, $5+0=5$, and so on.
We could break this deadlock by assuming that each of the $\Delta w_n \cdot x_n$ contributes equally to the error $e$. That is for each of the N contributing nodes, $\Delta w_n \cdot x_n = \frac{e}{N}$.
Is this
too naughty?! It might be, but we've done similar
cheeky things before with traditional neural networks, where the back propagation of the error is done by dividing it up heuristically, not by some sophisticated analysis.
We can now use this simpler expression and get $\Delta w_n$ on its own, which is what we want.
$$ \Delta w_n \cdot x_n = \frac{e}{N} $$
Normally we'd multiply both sides by $x^{-1}$. But remember, for complex numbers $x^{-1} = \frac{\bar{x}}{|x|}$. Remember also that the signals $x$ are on the unit circle so $|x|=1$, leaving $x^{-1}=\bar{x}$. That gives us,
$$ \Delta w_n = \frac{e}{N} \cdot \bar{x} $$
That's it! The learning rule ... no gradient descent, no differentiation ... just a simple
error correction rule.
Let's try it!
Experiment 1: Boolean OR, AND
The code for a single neuron, and a small complex valued neural network, learning the Boolean relations OR and AND are on
github.
So that's encouraging .. it works. We've shown the incredibly simple error correction learning method works - no need for derivatives and gradient descent.
But that test wasn't so challenging. Let's try a tougher test.
Periodic Activation Function
The complex valued neural node was easy to build and make, and experiments seem to confirm that it learns pretty quickly too.
But a simple node still has problems with the traditionally challenging problems like learning XOR. With a traditional neural network this needs multiple nodes to solve.
Aizenberg proposes that we can solve XOR with a single node, but to do that we need to make the activation function
periodic. What does this mean? It means we enrich the process of mapping the unit circle to an output class. Instead of dividing the circle in sectors, one sector for each class, we have multiple sectors for each class. Each sector is then smaller. Also the sectors for the same class can't be next to each other - that would defeat the idea! A picture shows this best:
The learning process is the same as before, but this time we have a choice of target sectors for each actual output during training. Look at the diagram above - if the training target was "grass" which one of the two do we choose? Remember, the error depends on how far the actual output is from the training target, and here we seem to have two "grass" targets.
What do we do? We pick the nearest one.
Let's try it!
Experiment 2: Boolean XOR
The code for a single complex neuron with a periodic activation function is on
github. We've used a periodicity of 2 for two classes (0, 1) .. which means a unit circle has four sectors corresponding to classes 0, 1, 0, 1.
It works! So we have a
single complex node, learning XOR .. something that wasn't possible with traditional neural nodes.
Let's now try it on the famous Iris dataset, which is more of a challenge for most learning algorithms.
Experiment 3: Fisher's Iris Dataset
The
Iris data set has a long history of challenging machine learning researchers. The data is simple enough - sepal and petal measurements of three species of Iris flower. The following scatterplot shows why it is a challenge - two of the three species have measurements which seem to intermingle into the same cluster.
Let's see how well a single complex neutron with a periodic activation function does.
The code is a
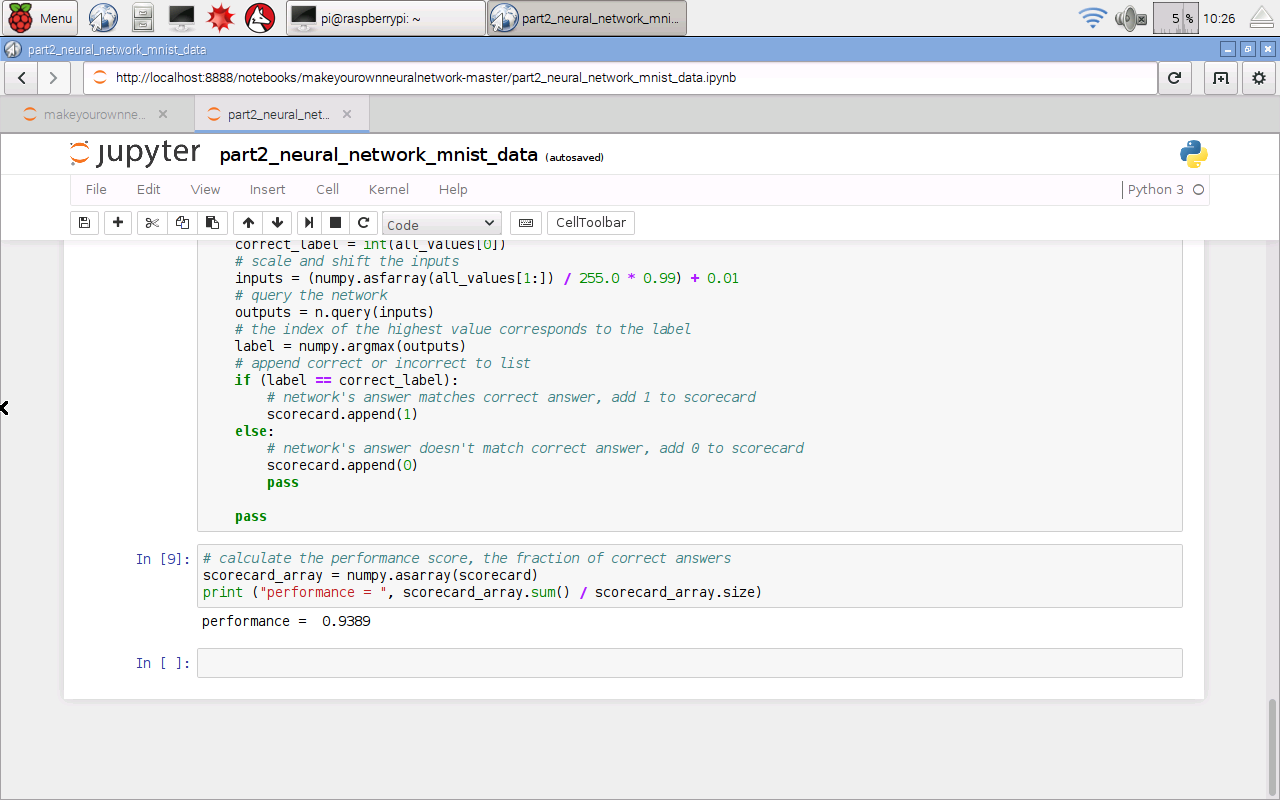
github, and the following shows that with a periodicity of 3, we get
94.7% performance against a randomly partitioned test dataset (25% of the data set).
That is not bad at all! In fact, that's
really rather impressive!
Microsoft's more complex
example achieves 97% .. so we're not doing badly at all with very simple ideas and code .. and remember, only a single neuron!
Again ... to emphasise this ... an academic paper [
PDF, table 2] shows similar scores of 95-97% using more complex networks.
How do we choose the right periodicity? I don't know. At this stage it is trial and error to choose the right periodicity.
Conclusion
We've achieved:
- a very simple approach to neural networks that reflects the importance of phase
- a super simple learning algorithm that avoids differentiation and gradient descent
- a powerful approach to learn non-threshold functions like XOR
- performance amongst the best from just a single complex neuron
Next time we'll see how these complex neurons can be combined into networks, and also see if we get good results from the MNIST handwriting challenge.
The ideas here are inspired by Igor Aizenberg, see more at his university course page.