Below is the updated section, and the diagram has also been updated too.
Let’s press on to the second training data example at x = 1.0. Using A = 0.3083 we have y = 0.3083 * 1.0 = 0.3083. The desired value was 2.9 so the error is (2.9 - 0.3083) = 2.5917. The ΔA = L (E / x) = 0.5 * 2.5917 / 1.0 = 1.2958. The even newer A is now 0.3083 + 1.2958 = 1.6042.
Let’s visualise again the initial, improved and final line to see if moderating updates leads to a better dividing line between ladybird and caterpillar regions.
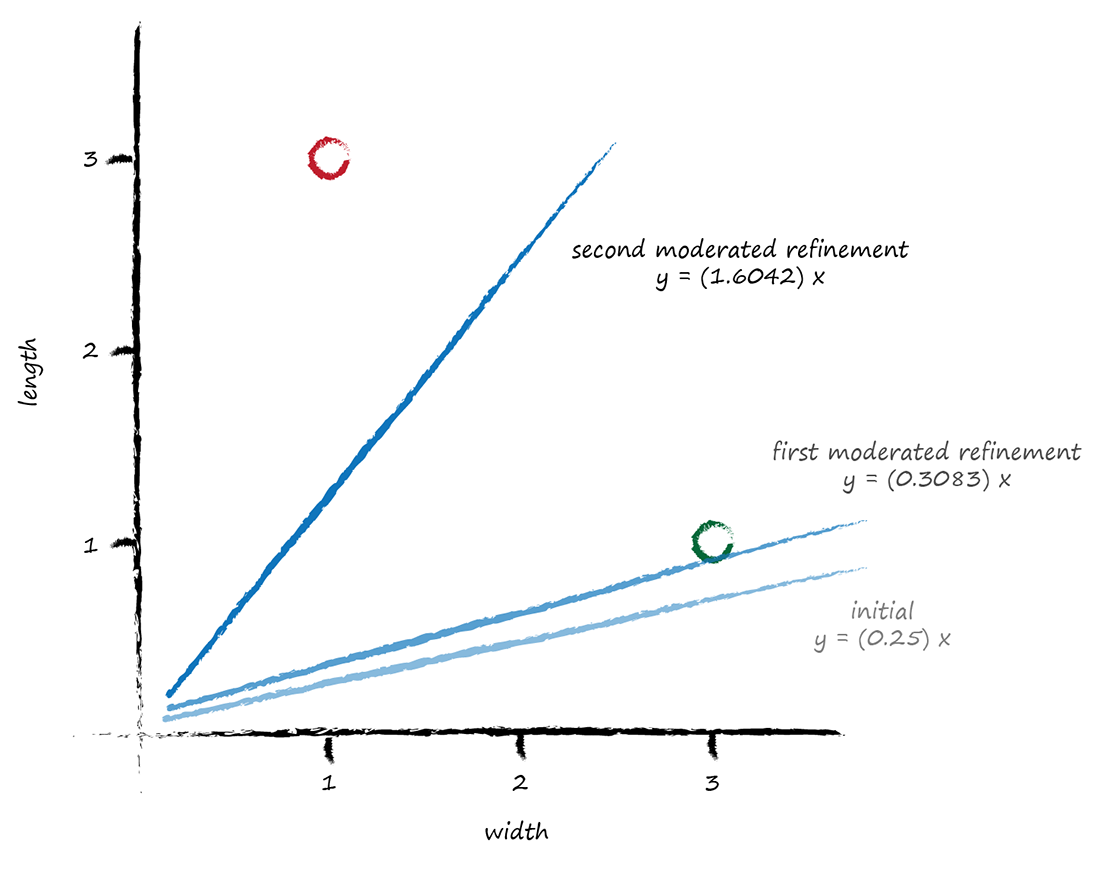
This is really good!
Even with these two simple training examples, and a relatively simple update method using a moderating learning rate, we have very rapidly arrived at a good dividing line y = Ax where A is 1.6042.
The ebook has been updated and you should get an automatic update, or ask Amazon to trigger an update if it is slow to get to you. The print book has also been updated.